


Итак, дорогие хабровчане, хочу представить на ваше обозрение инструкцию, как нам пришлось поднимать OLAP-сервер в нашей компании. Шаг за шагом мы пройдем по пути, который был нами проделан, начиная с установки и настройки Pentaho и заканчивая подготовкой таблиц данных и публикацией olap-куба на сервере. Естественно, многое здесь может быть сумбурным/неточным/неоптимальным, но когда нам понадобилось поднять сервер и посмотреть, сможет ли Pentaho заменить нашу самописную статистику, у нас не было и такого…
Весь процесс поднятия OLAP-сервера я разбил на 3 части:
- настройка Pentaho BI Server
- подготовка таблиц фактов и измерений
- создание куба и публикация его на сервере
Настройка Pentaho BI Server
Устанавливаем JDK.
Выставляем переменные окружения:
JAVA_HOME=c:\Program Files\Java\jdk1.7.0_15
JRE_HOME=c:\Program Files\Java\jdk1.7.0_15\jre
PENTAHO_JAVA_HOME=c:\Program Files\Java\jdk1.7.0_15
Скачиваем и распаковываем свежую версию Pentaho Business Intelligence (biserver-ce-4.8.0-stable.zip). Я залил содержимое архива (папки administration-console и biserver-ce) в папку c:\Pentaho. Итак, распаковать — распаковали, но сервер пока еще не сконфигурирован. Этим мы сейчас и займемся…
Скачиваем MySQL-коннектор для Java (mysql-connector-java-5.1.23-bin.jar). Закидываем его в папку c:\Pentaho\biserver-ce\tomcat\lib.
По умолчанию Pentaho использует движок HSQLDB, т.е. создает и хранит все базы данных в памяти, в том числе тестовую базу sampledata. Это еще нормально для небольших таблиц (таких, как демо), но для боевых данных обычно движок меняют на MySQL или Oracle, например. Мы будем использовать MySQL.
Заливаем в MySQL базы hibernate и quartz. Обе они используется под системные нужды Pentaho. Качаем отсюда файлы 1_create_repository_mysql.sql и 2_create_quartz_mysql.sql. Импортим их в MySQL.
Теперь наш MySQL-сервер настроен как репозиторий Pentaho. Подконфигурируем Pentaho-сервер для использования этого репозитория по умолчанию. Для этого будем править следующие xml-ки:
1. \pentaho-solutions\system\applicationContext-spring-security-hibernate.properties
Меняем driver, url и dialect на com.mysql.jdbc.Driver, jdbc:mysql://localhost:3306/hibernate и org.hibernate.dialect.MySQL5Dialect соответственно.
2. \tomcat\webapps\pentaho\META-INF\context.xml
Меняем параметры driverClassName на com.mysql.jdbc.Driver, параметры url на jdbc:mysql://localhost:3306/hibernate и jdbc:mysql://localhost:3306/quartz соответственно в 2-х секциях, параметры validationQuery меняем на select 1.
3. \pentaho-solutions\system\hibernate\hibernate-settings.xml
В параметре меняем hsql.hibernate.cfg.xml на mysql5.hibernate.cfg.xml.
4. \pentaho-solutions\system\simple-jndi\jdbc.properties
Удаляем весь ненужный хлам кроме Hibernate и Quartz.
5. Сносим папки \pentaho-solutions\bi-developers, \pentaho-solutions\plugin-samples и \pentaho-solutions\steel-wheels. Это тестовые данные, которые нам нужны в принципе не будет.
6. \tomcat\webapps\pentaho\WEB-INF\web.xml
Удаляем или комментим все сервлеты секций [BEGIN SAMPLE SERVLETS] и [BEGIN SAMPLE SERVLET MAPPINGS], кроме ThemeServlet.
Удаляем секции [BEGIN HSQLDB STARTER] и [BEGIN HSQLDB DATABASES].
Удаляем строки:
<filter-mapping>
<filter-name>SystemStatusFilter</filter-name>
<url-pattern>/*</url-pattern>
</filter-mapping>
7. Удаляем каталог \data. Этот каталог содержит тестовую БД, скрипты для запуска этой БД и инициализации репозитория Pentaho.
8. \pentaho-solutions\system\olap\datasources.xml
Удаляем каталоги с именами SteelWheels и SampleData.
9. \pentaho-solutions\system\systemListeners.xml
Удаляем или комментим строку:
<bean id="pooledDataSourceSystemListener" class="org.pentaho.platform.engine.services.connection.datasource.dbcp.PooledDatasourceSystemListener" />
10. \tomcat\webapps\pentaho\WEB-INF\web.xml
Указываем наш solution-path: c:\Pentaho\biserver-ce\pentaho-solutions.
11. \system\sessionStartupActions.xml
Закомментим или удалим все блоки ....
Настраиваем web-морду Pentaho
После всех манипуляций с конфигами, можно уже и подзапустить чего-нибудь. Идем в папку с нашим сервером и запускаем start-pentaho.bat или sh-шник, кому что нужно в его операционной системе. По идее, никаких ERROR’ов в консоли или логах томката быть уже не должно.
Итак, если все прошло гладко, то по адресу localhost:8080 отобразится форма входа:
Вводим стандартный логин/пароль (joe/password) и попадаем внутрь. Теперь нужно установить olap-клиент, который и будет, собственно, отображать наши к нему запросы. У платной версии Pentaho есть свой клиент, для CE мы использовали плагин Saiku.
Заходим в пункт Pentaho Marketplace верхнего меню, устанавливаем Saiku Analytics.
Тут пока всё, пришло время подготовки данных для аналитики.
Подготовка таблиц фактов и измерений
Pentaho — это ROLAP-реализация технологии OLAP, т.е. все данные, которые мы будем анализировать, хранятся в обычных реляционных таблицах, разве что, возможно, некоторым образом заранее подготовленных. Поэтому все, что нам нужно, — это создать нужные таблицы.
Скажу немного о предметной области, для которой нам нужна была статистика. Есть сайт, есть клиенты и есть тикеты, которые эти клиенты могут писать. Еще и с комментариями, да. И все эти тикеты наш саппорт разбивает по разным тематикам, проектам, странам. И вот нам было нужно, например, узнать, сколько тикетов по тематике «Доставка» пришло с каждого проекта из Германии за прошлый месяц. И все это разбить по админам, т.е. посмотреть кто из саппорта и сколько таких тикетов обработал и т.д. и т.п.
Все подобные срезы технология OLAP и позволяет проводить. Про сам OLAP подробно рассказывать не стану. Будем считать, что с понятиями OLAP-куба, измерений и мер читатель знаком и в общих чертах представляет себе, что это такое и с чем это едят.
Конечно, реальные данные реальных клиентов я в качестве примера разбирать не буду, а для этой цели воспользуюсь своим небольшим сайтом с футбольной статистикой. Практической пользы от этого немного, но в качестве образца — самое оно.
Итак, есть таблица players. Попробуем найти всякую-разную полезную и не очень статистику: количество игроков каждой страны, количество игроков по амплуа, количество действующих игроков, количество российских полузащитников в возрасте от 30 до 40 лет. Ну что-то вроде такого…
Итак, на чем я остановился? А, точно, подготовка таблиц. Тут есть несколько способов: воссоздать все таблицы руками и голыми SQL-никами или воспользоватся утилитой Pentaho Data Integration (PDI, также известная как Kettle) — компонент комплекса Pentaho, отвечающий за процесс извлечения, преобразования и выгрузки данных (ETL). Она позволяет установить соединение с определенной БД и с помощью уймы различных инструментов подготовить нужные нам таблицы. Скачиваем её. Закидываем mysql-коннектор в папку lib и запускаем PDI через Spoon.bat.
Сначала соберем сердце нашей статистики — таблицу игроков. Изначально ее структура выглядит как-то так:
CREATE TABLE IF NOT EXISTS `player` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT COMMENT 'ID',
`name` varchar(40) DEFAULT NULL COMMENT 'Имя',
`patronymic` varchar(40) DEFAULT NULL COMMENT 'Отчество',
`surname` varchar(40) DEFAULT NULL COMMENT 'Фамилия',
`full_name` varchar(255) DEFAULT NULL COMMENT 'Полное имя',
`birth_date` date NOT NULL COMMENT 'Дата рождения',
`death_date` date DEFAULT NULL COMMENT 'Дата смерти',
`main_country_id` int(11) unsigned NOT NULL COMMENT 'ID страны',
`birthplace` varchar(255) DEFAULT NULL COMMENT 'Место рождения',
`height` tinyint(3) unsigned DEFAULT NULL COMMENT 'Рост',
`weight` tinyint(3) unsigned DEFAULT NULL COMMENT 'Вес',
`status` enum('active','inactive') NOT NULL DEFAULT 'active' COMMENT 'Статус игрока - играет, завершил карьеру и т.д.',
`has_career` enum('no','yes') NOT NULL DEFAULT 'no' COMMENT 'Есть ли подробная статистика по карьере',
PRIMARY KEY (`id`),
KEY `name` (`name`),
KEY `surname` (`surname`),
KEY `birth_date` (`birth_date`),
KEY `death_date` (`death_date`),
KEY `has_stat` (`has_career`),
KEY `main_country_id` (`main_country_id`),
KEY `status` (`status`),
KEY `full_name_country_id` (`full_name_country_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='Игроки' AUTO_INCREMENT=1;
Часть полей (name, surname, patronymic, full_name или birthplace, например) для статистики не нужна. Поля типа Enum (status, has_career) нужно вынести в отдельные таблицы измерений, а в основной таблице просто проставить айдишники внешних ключей.

Итак, приступим: File > New > Job (Ctrl+Alt+N). Откроется рабочая область задания. Переходим во вкладку View, создаем новое соединение с БД (Database connections > New): вбиваем сервер, БД, пользователя и пароль, даем соединению какое-нибудь имя (у меня fbplayers) и сохраняем (c:\Pentaho\biserver-ce\pentaho-solutions\jobs\fbplayers.kjb).
Создаем трансформацию (File > New > Transformation, Ctrl+N). Сохраним ее под именем prepare_tables.ktr. Точно так же как и с заданием (job), добавляем коннект к БД для трансформации. Готово.
Переходим во вкладку View и раскрываем раздел Input. Выбираем инструмент Data Grid. Он хорошо подходит, если нужно вынести какие-то поля с небольшим количеством возможных вариантов в отдельные связанные таблицы. Итак, вытягиваем Data Grid в рабочую область и открываем ее для редактирования двойным кликом. Вбиваем название данного шага трансформации (Player Status), начинаем задавать структуру данной таблицы (вкладка Meta) и сами данные (вкладка Data). В структуре имеем 2 поля:
1. Name — id, Type — Integer, Decimal — 11
2. Name — status, Type — String, Length — 10.
Во вкладке Data вбиваем 2 строки: 1 — active, 2 — inactive.
Переходим в раздел Output и вытягиваем оттуда элемент Table Output. Двойной щелчок, задаем имя элемента как Player Status Dim. Коннект должен отобразиться в следующей строчке. В поле Target Table пишем название таблицы, которая будет создана в БД для хранения статуса игроков: player_status_dim. Ставим чекбокс Truncate Table. Связываем входной и выходной элементы: щелкаем по Player Status и с зажатой кнопкой Shift тянем мышь на Player Status Dim. Связь должна появиться в виде стрелки, соединяющей эти элементы.
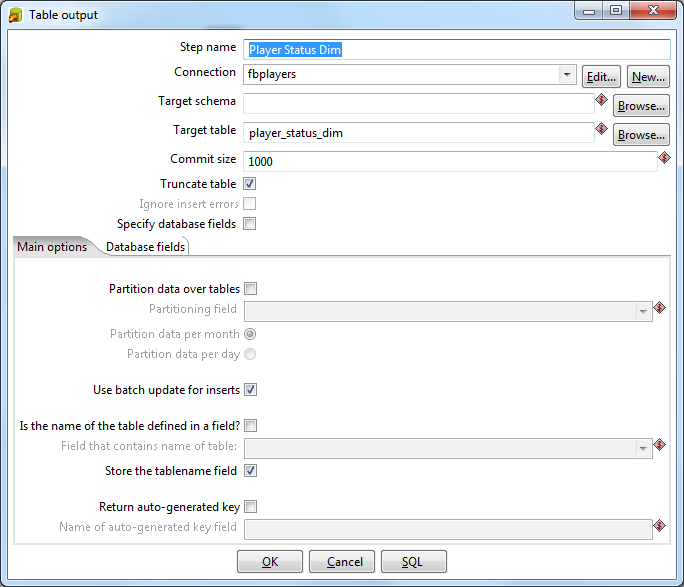
Такую же штуку нужно провернуть с флажком для карьеры (Player Career):
1. Name — id, Type — Integer, Decimal — 11
2. Name — has_career, Type — String, Length — 3.
Во вкладке Data вбиваем 2 строки: 1 — no, 2 — yes.
Точно также собираем выходную таблицу Player Career Dim.
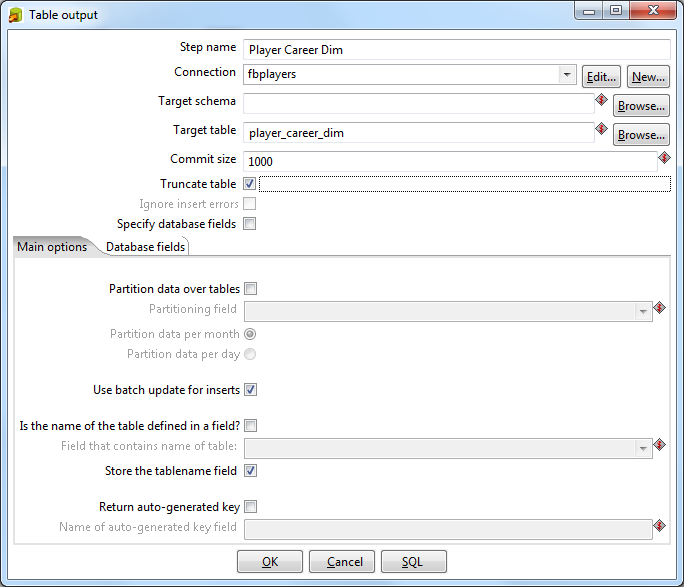
Теперь вынесем дату рождения игрока в отдельную таблицу измерений. По большому счету, Pentaho позволяет использовать дату прямо в таблице фактов, изначально мы так и делали с данными нашей предметной области. Но возникло несколько проблем:
1. если нужно разбить 2 разные таблицы фактов (например, Игроки и Тренеры) по дате рождения, то нужно общее для них измерение (Dimension);
2. при разбиении даты, лежащей в самой таблице фактов, на составляющие части функции типа extract или year (month, …) будет применяться к каждой строке таблицы для получения года, месяца и т.д. Что не айс.
Итак, по этим причинам мы переделали нашу изначальную структуру и создали таблицу со всеми уникальными значениями времени, оставив минимальным уровнем часы. Для нашего тестового примера такой детализации не будет, будут только года, месяцы и дни.
Создадим новую трансформацию (initial_sql). Не забываем про коннект. Из коллекции элементов выбираем Scripting > Execute SQL Script. В него пишем сборщик дат:
DROP TABLE IF EXISTS `player_birth_date_dim`;
CREATE TABLE IF NOT EXISTS `player_birth_date_dim` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT COMMENT 'ID',
`year` smallint(5) unsigned NOT NULL COMMENT 'Год',
`month` tinyint(2) unsigned NOT NULL COMMENT 'Месяц',
`day` tinyint(2) unsigned NOT NULL COMMENT 'День',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='Измерение времени' AUTO_INCREMENT=1 ;
INSERT INTO `player_birth_date_dim`
(SELECT DISTINCT NULL, YEAR(p.birth_date) as `year`,
MONTH(p.birth_date) as `month`, DAY(p.birth_date) as `day`
FROM (
SELECT DISTINCT birth_date FROM player
) AS p)
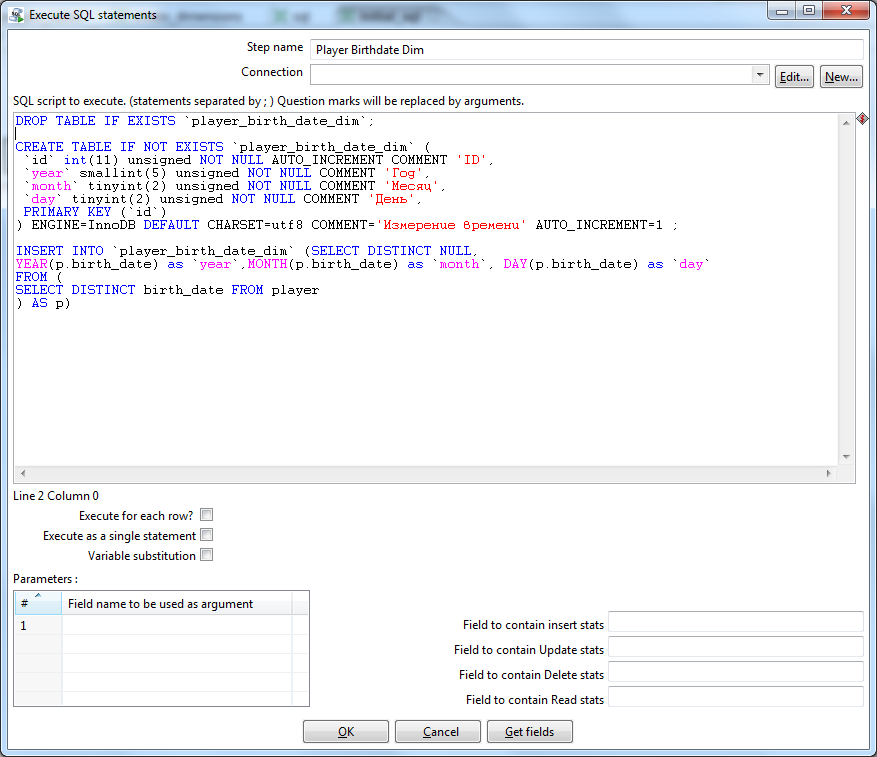
Тут же, в этой трансформации, создаем еще 2 SQL-скрипта — для создания таблицы Player Career Dim и Player Status Dim:
DROP TABLE IF EXISTS player_career_dim;
CREATE TABLE IF NOT EXISTS `player_career_dim` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT COMMENT 'ID',
`has_сareer` varchar(3) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 AUTO_INCREMENT=1 ;
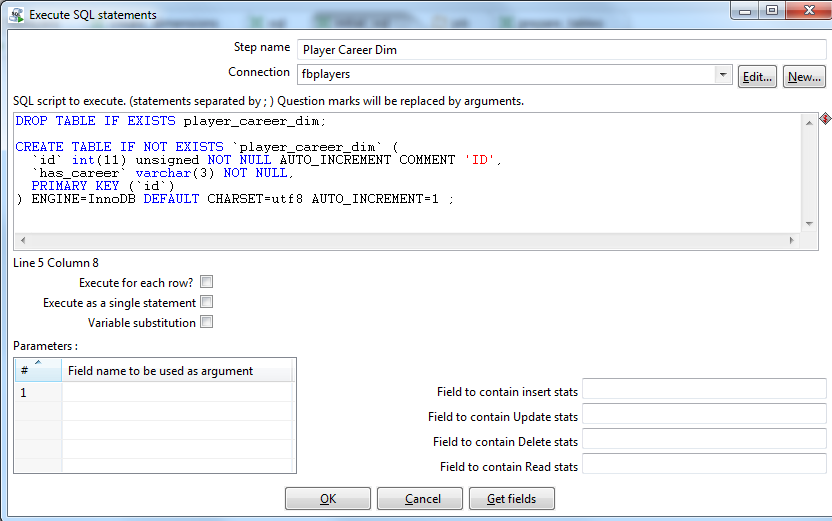
DROP TABLE IF EXISTS player_status_dim;
CREATE TABLE IF NOT EXISTS `player_status_dim` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT COMMENT 'ID',
`status` varchar(10) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 AUTO_INCREMENT=1 ;

Приступаем к основной части нашей миссии — сборке таблицы фактов. Создаем трансформацию (player_fact.ktr). Про коннект не забыли, правда? Из вкладки Input кидаем Table Input, из Output — Table Output соответственно. В Table Input пишем клёвый SQL-ник:
SELECT
p.id AS player_id,
dd.id AS birth_date_id,
p.main_country_id,
p.height,
p.weight,
CASE p.status
WHEN 'active' THEN 1
WHEN 'inactive' THEN 2
END as status_id,
CASE p.has_career
WHEN 'no' THEN 1
WHEN 'yes' THEN 2
END as has_career_id
FROM player AS `p`
INNER JOIN player_birth_date_dim AS dd
ON YEAR(p.birth_date) = dd.`year`
AND MONTH(p.birth_date) = dd.`month` AND DAY(p.birth_date) = dd.`day`
В Table Output указываем имя таблицы — player_fact. Связываем исходную и результирующую таблицы стрелкой.
Опять идем в наш job. Из вкладки General добавляем новую трансформацию. Открываем ее, даем имя Prepare Tables и указываем путь до нашей сохраненной трансформации prepare_tables.ktr.
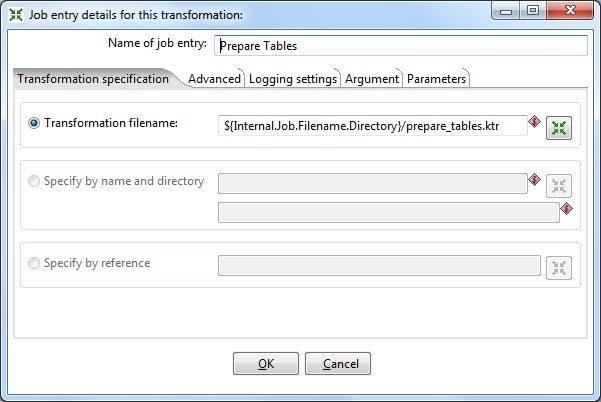
То же самое делаем с трансформациями Initial SQL и Player Fact.
Закидываем на форму кнопку Start и соединяем элементы в следующей последовательсти: Start > Initial SQL > Prepare Tables > Load Player Fact.
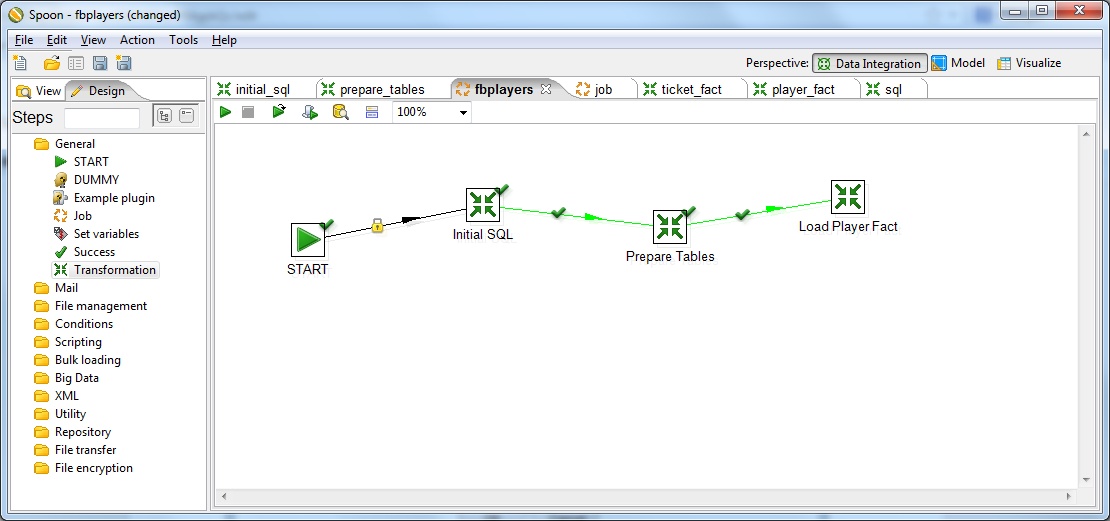
Теперь можно попробовать запустить задание. В панели инструментов жмакаем зеленый треугольник. Если наши руки были достаточно прямы, то около каждого из наших элементов мы увидим зеленую галочку. Можно зайти на свой сервер и проверить, что таблички действительно созданы. Если что-то пошло не так, то лог покажет все наши грешки.
Создание куба и публикация его на сервере
Теперь, когда у нас есть подготовленные данные, займемся, наконец, и OLAP-ом. Для создания olap-кубов у Pentaho есть утилита Schema Workbench. Скачиваем, распаковываем, закидываем mysql-коннектор в папку drivers, запускаем workbench.bat.
Сразу же заходим в меню Options > Connection. Вводим наши параметры подключения к БД.
Приступаем: File > New > Schema. Сразу сохраним схему (у меня fbplayers.xml). Зададим имя схеме.
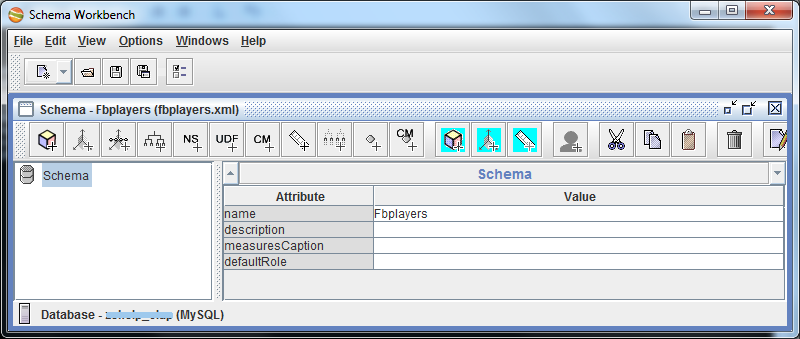
Через контекстное меню схемы создаем куб. Назовем его именем сущности, статистику по которой будем считать, т.е. Player.
Внутри куба указываем таблицу, которая будет у нас таблицей фактов: player_fact.
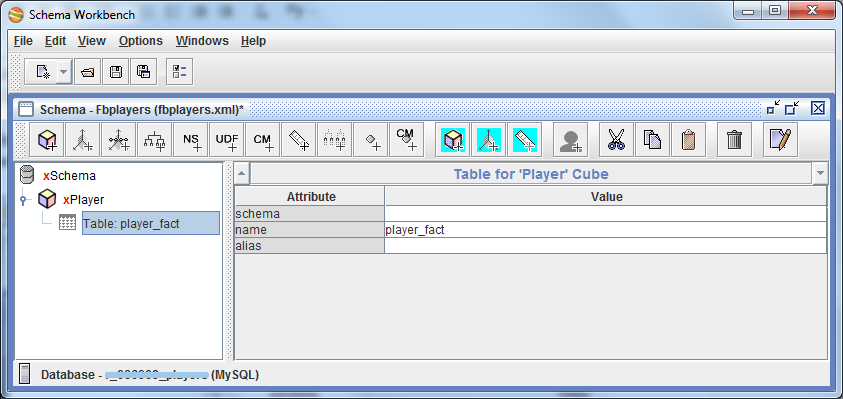
Если выбрать куб Player, то красная строчка внизу правой области подскажет нам, что в кубе должны быть заданы измерения (Dimensions), т.е. те параметры, по которым будут производиться срезы данных.
Есть 2 способа задать измерение кубу: непосредственно внутри него (через Add Dimension) и внутри схемы (Add Dimension у схемы плюс Add Dimension Usage у самого куба). Мы в своей статистике использовали второй вариант, т.к. он позволяет одно измерение применить к нескольким таблицам фактов сразу (к нескольким кубам). Эти кубы мы потом объединили в виртуальный куб, что позволило нам выводить статистику по нескольким кубам одновременно.
В нашем тестовом проекте мы также воспользуемся вторым способом, разве что не будем создавать виртуальные кубы.
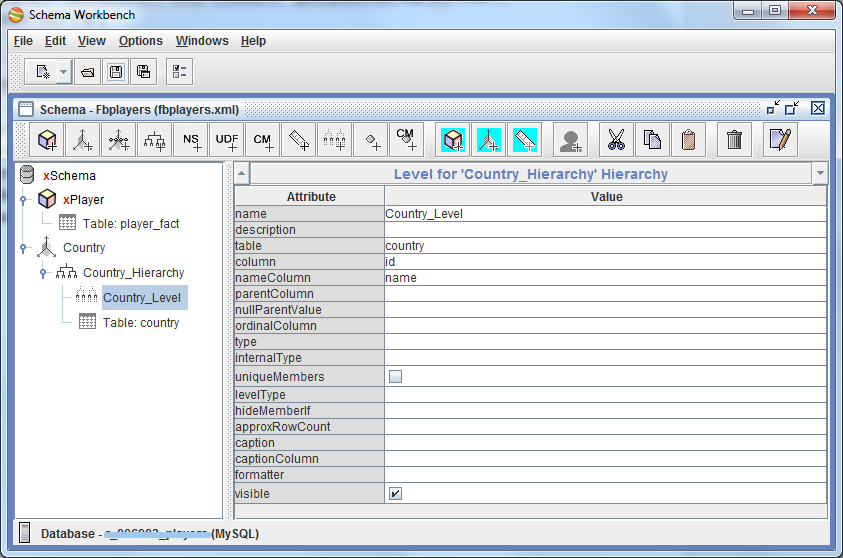
Итак, добавим первое измерение (по стране). Создаем измерение схемы, даем ему имя Country. Внутри него уже есть 1 иерархия, ей зададим имя Country_Hierarchy. В эту иерархию добавляем таблицу, которая хранит значения измерения Country, т.е. country.
Это моя обычная mysql-таблица со списком стран следующей структуры:
CREATE TABLE IF NOT EXISTS `country` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT COMMENT 'ID',
`name` varchar(40) NOT NULL COMMENT 'Название',
`english_name` varchar(40) NOT NULL COMMENT 'Название на английском',
`iso_alpha_3` varchar(3) NOT NULL COMMENT 'Трехбуквенный код ISO 3166-1',
PRIMARY KEY (`id`),
KEY `name` (`name`),
KEY `england_name` (`english_name`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='Страны' AUTO_INCREMENT=1 ;
После этого добавляем в иерархию 1 уровень (Add Level). Назовем его Country_Level и свяжем таблицу фактов с этой таблицей измерения: поле table выставляем в country, column — в id, nameColumn — в name. Т.е. это значит, что при сопоставлении ID страны из таблицы фактов ID страны из таблицы country в качестве результата вернется название страны (для читабельности). Остальные поля в принципе можно и не заполнять.
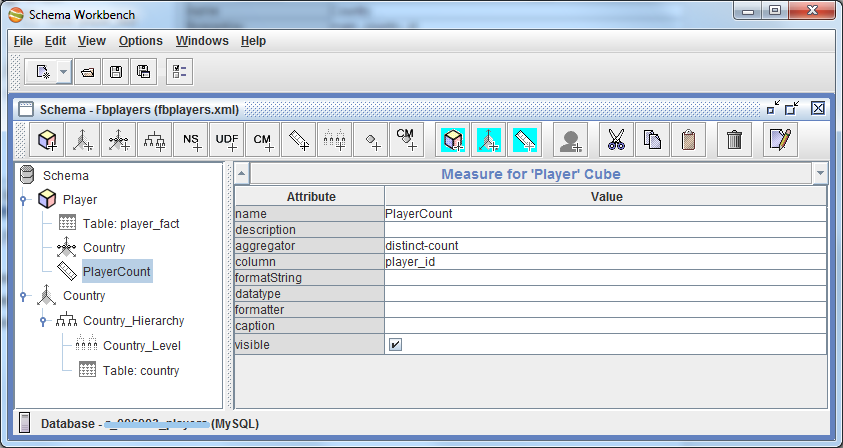
Теперь мы можем вернуться к кубу Player и задать ему только что созданное измерение (через Add Dimension Usage). Задаем имя (Country), source — это наше созданное измерение Country (в выпадающем списке оно и будет пока единственным), а поле foreignKey — main_country_id, т.е. это говорит Pentaho, что когда он видит какой-то main_country_id в таблице фактов, он обращается к таблице измерения (Country) по указанному столбцу (id) и подставляет на место main_country_id значение name. Как-то так…

Осталось только указать кубику, что мы собственно хотим агрегировать-то )) Добавляем в куб меру (Add Measure). Зададим ей имя PlayerCount, агрегатор — distinct-count и поле, по которому будем агрегировать — player_id. Готово!
Давайте остановимся на этом ненадолго и проверим, что мы тут наколдовали. Запускаем веб-морду Pentaho: localhost:8080/pentaho (не забываем про start-pentaho.bat). Заходим в File > Manage > Data Sources. Жмем кнопку добавления нового источника. Выбираем тип — Database Table(s). Самое важное, что нам тут нужно — это создать новое соединение (Connection). Задаем имя (Fbplayers) и вбиваем наши данные для доступа к БД. После сохранения Connection’а, жмем везде Cancel, больше нам тут ничего не нужно.
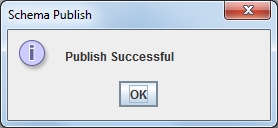
Далее нам нужно опубликовать созданную схему на сервере Pentaho: File > Publish. Задаем урл: localhost:8080/pentaho и вводим пароль на публикацию. Этот пароль задается в файлике c:\Pentaho\biserver-ce\pentaho-solutions\system\publisher_config.xml. Установим этот пароль в 123, например, юзер и пароль стандартные — joe/password. Если все нормально, то после должно отобразиться окно выбора папки, куда сохранять нашу схему. Вводим имя соединения, которое мы создали на прошлом шаге (Fbplayers) в поле «Pentaho or JNDI Source». Создадим папку schema и сохраним файл в нее. Если все прошло нормально, мы должны увидеть радостное окошко:
Пойдемте глядеть! Заходим на веб-морду, открываем Saiku, выбираем наш куб из выпадающего списка. Видим появившиеся измерение Country и меру PlayerCount. Перетягиваем Country_Level в поле Rows, PlayerCount — в Columns. По умолчанию, на панели Saiku вжата кнопка автоматического выполнения запроса. Обычно стоит ее отжать перед натаскиванием измерений и мер, но это не принципиально. Если автоматическое выполнение отключено, жмем кнопку Run. Радуемся!
Но если вдруг вместо красивых данных вы увидели сообщение вроде “EOFException: Can not read response from server. Expected to read 4 bytes, read 0 bytes before connection was unexpectedly lost”, не волнуйтесь — это бывает, просто нажмите Run еще раз-другой.
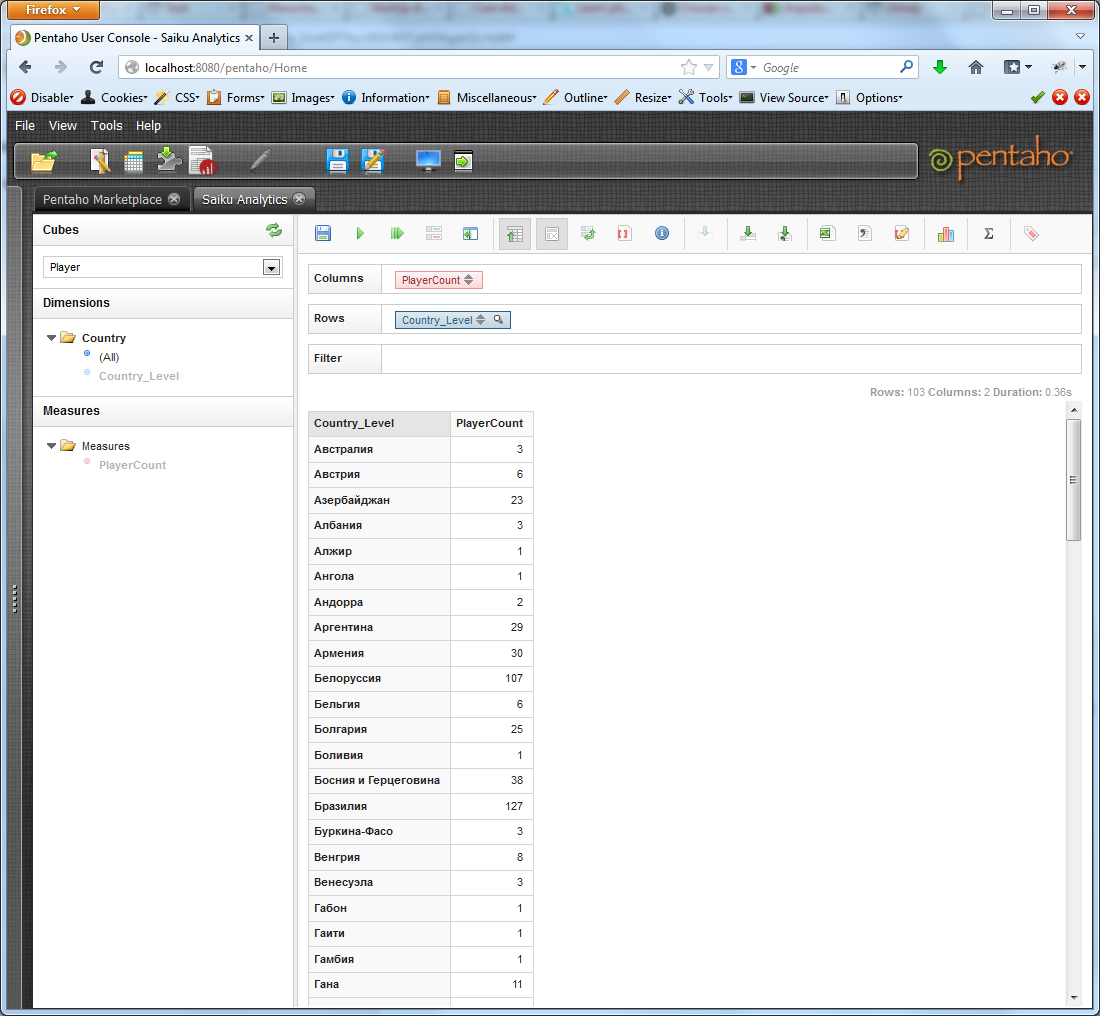
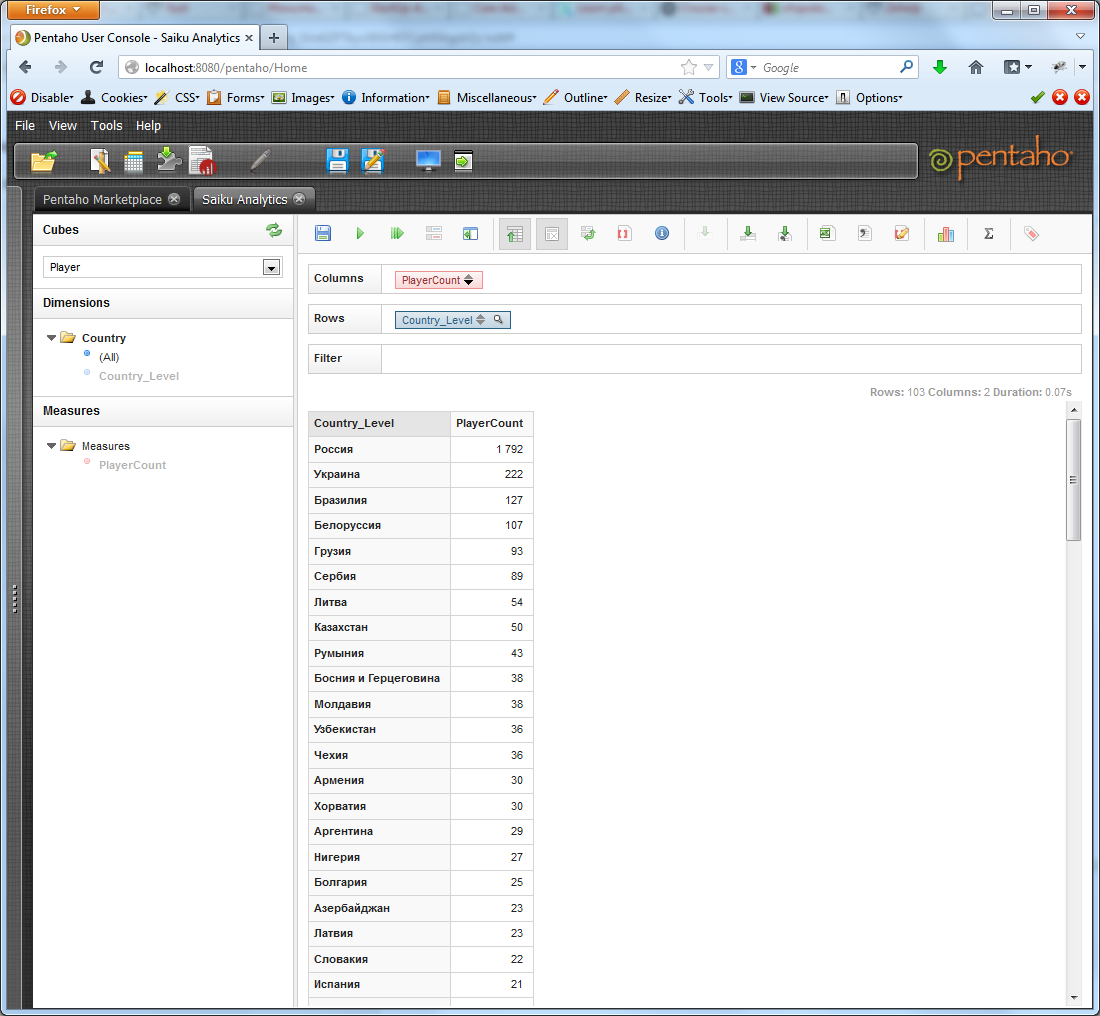
Щелчком по стрелочкам на кнопке меры, мы можем отсортировать результирующую выборку по убыванию или возрастанию.
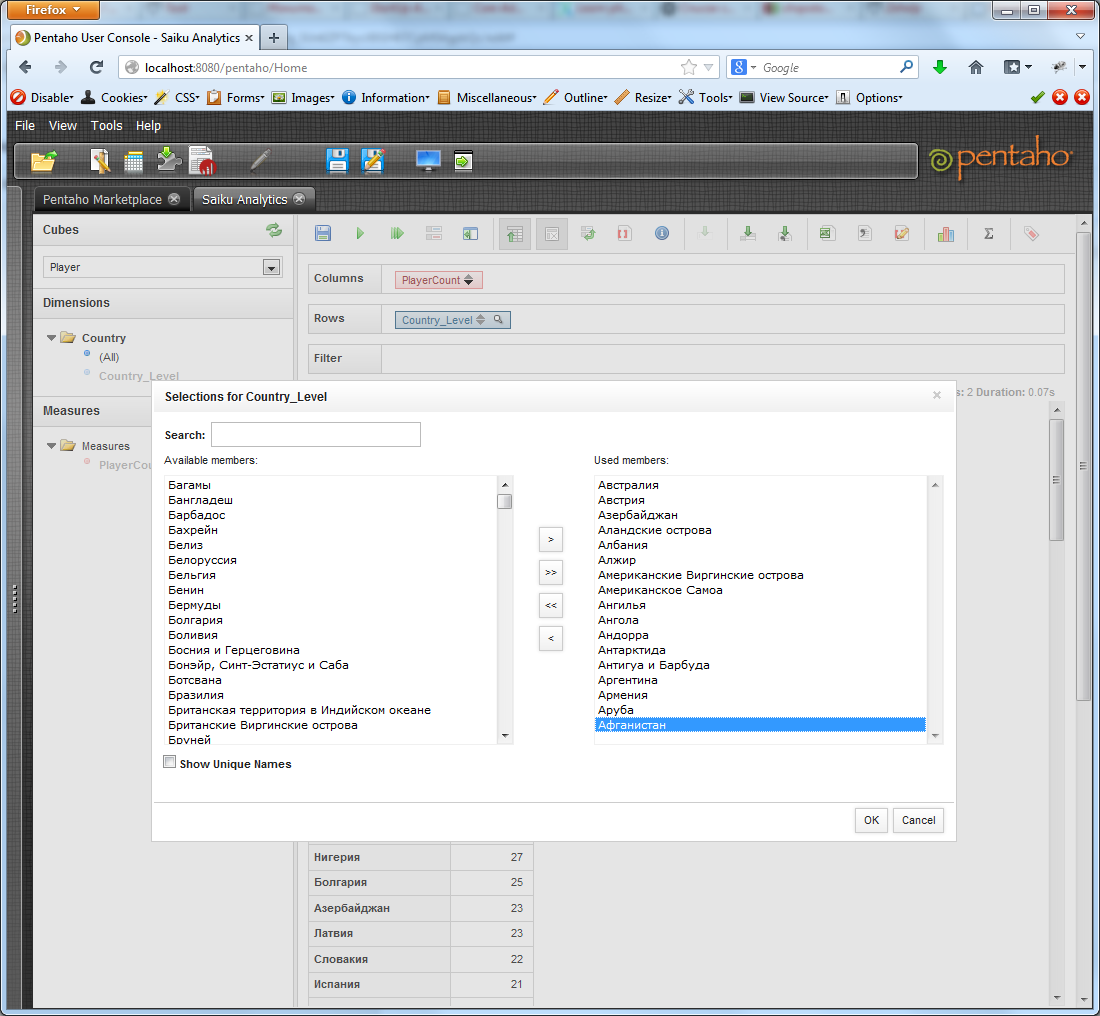
Пока у нас немного данных, давайте посмотрим, что у нас еще доступно. Можно ограничить выводимые данные, скажем, только по странам на букву А:
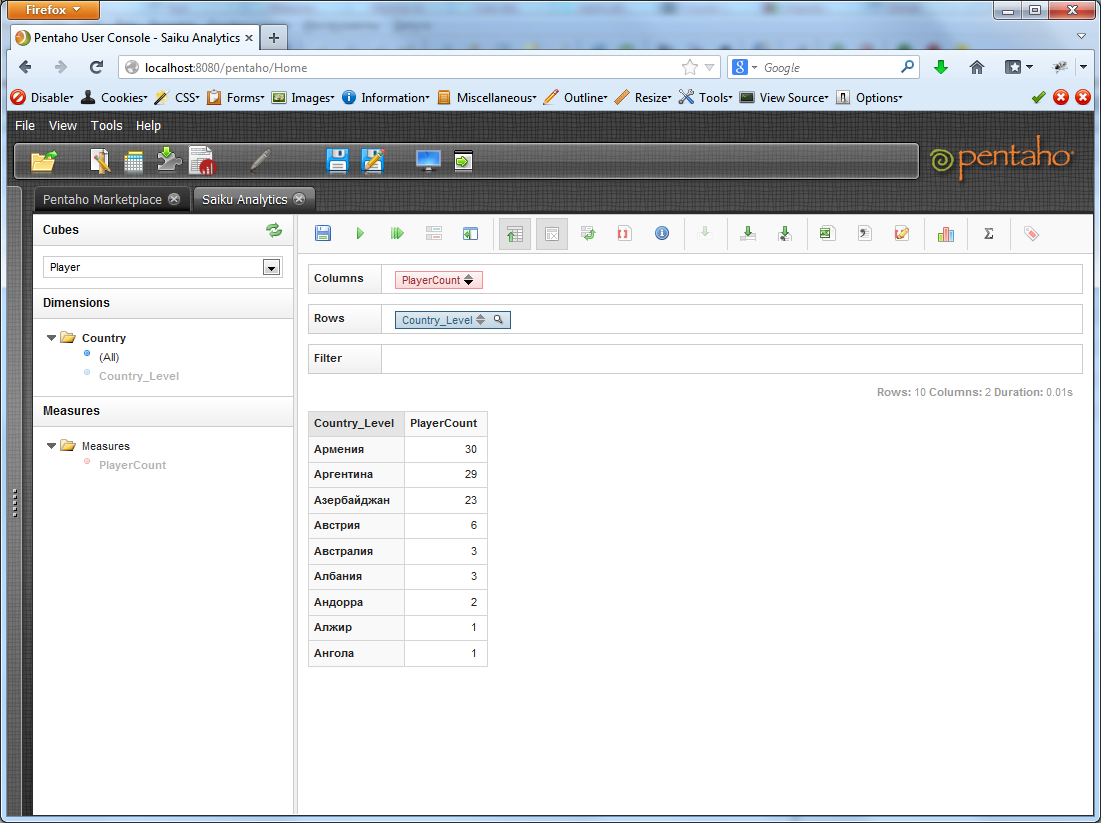
Получим:
Можно посмотреть графики. Обычно это красиво, если в выборке немного данных.
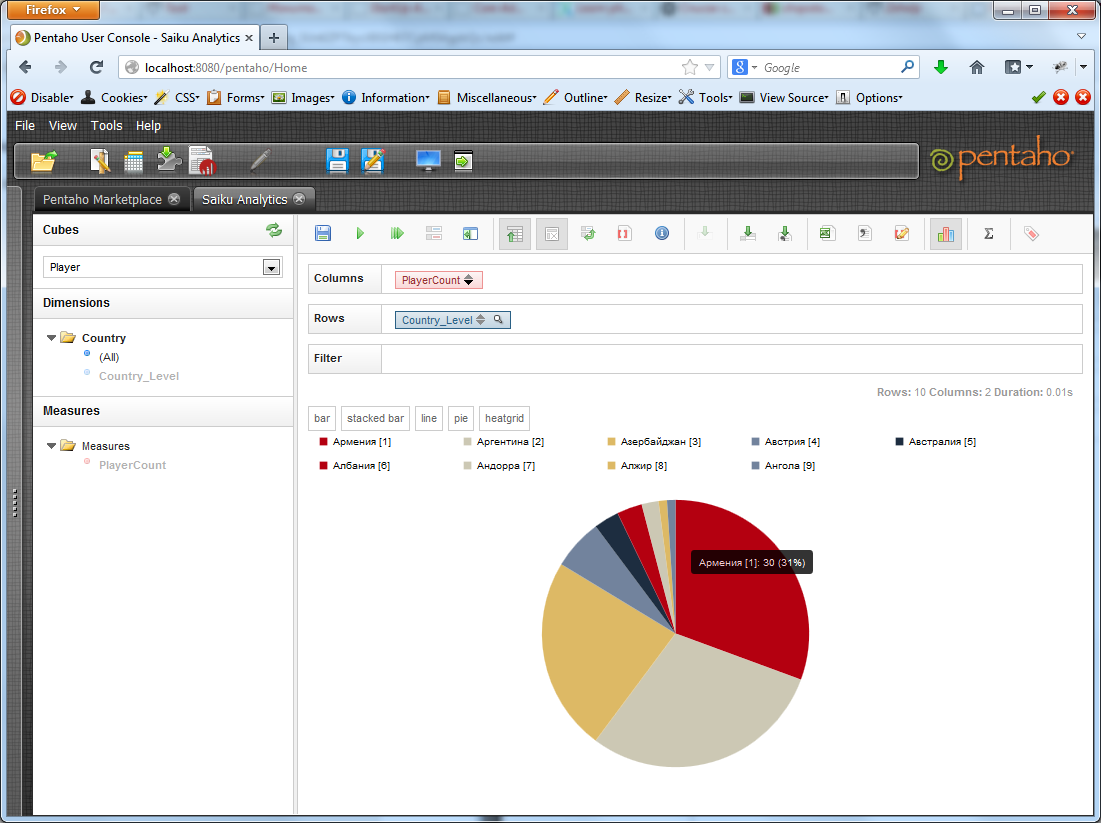
Можно посмотреть статистику по выборке: минимальный, максимальный показатель, среднее значение и т.д. Можно выгрузить все это достояние в xls или csv. Также накиданный нами с помощью конструктора запрос можно сохранить на сервере, чтобы потом вернуться к нему.
Итак, суть понятна. Давайте создадим еще пару измерений. В принципе, измерения по статусу игрока и наличию карьеры ничем не отличаются от измерения по стране. Да и результатом и в том, и в другом случае будут всего 2 строки (active/inactive и has/no).
Гораздо интереснее обстоит дело с иерархией типа Дата. Ее мы сейчас и создадим. Возвращаемся в Workbench, добавляем новое измерение (BirthDate). Ему вместо StandardDimension выставляем параметр TimeDimension. Иерархия здесь уже есть. Добавляем таблицу измерения — player_birth_date_dim.
Добавляем первый уровень — Year. Задаем значения table = player_birth_date_dim, column = id, levelType = TimeYears. Для данного уровня добавляем свойство Key Expression со значением `year`.
Добавляем второй уровень — Month. Задаем значения table = player_birth_date_dim, column = id, levelType = TimeMonths. Для данного уровня добавляем свойство Key Expression со значением `month`, Caption Expression со значением “CONCAT(`year`, ‘, ‘, MONTHNAME(STR_TO_DATE(`month`, ‘%m’)))”.
Добавляем третий уровень — Day. Задаем значения table = player_birth_date_dim, column = id, levelType = TimeDays. Для данного уровня добавляем свойство Caption Expression со значением “CONCAT(LPAD(`day`, 2, 0), ‘.’, LPAD(`month`, 2, 0), ‘.’, `year`)”.
Добавляем созданное измерение в куб, в качестве foreignKey указав bith_date_id.
Публикуем. Попробуем разбить всех игроков по году рождения.
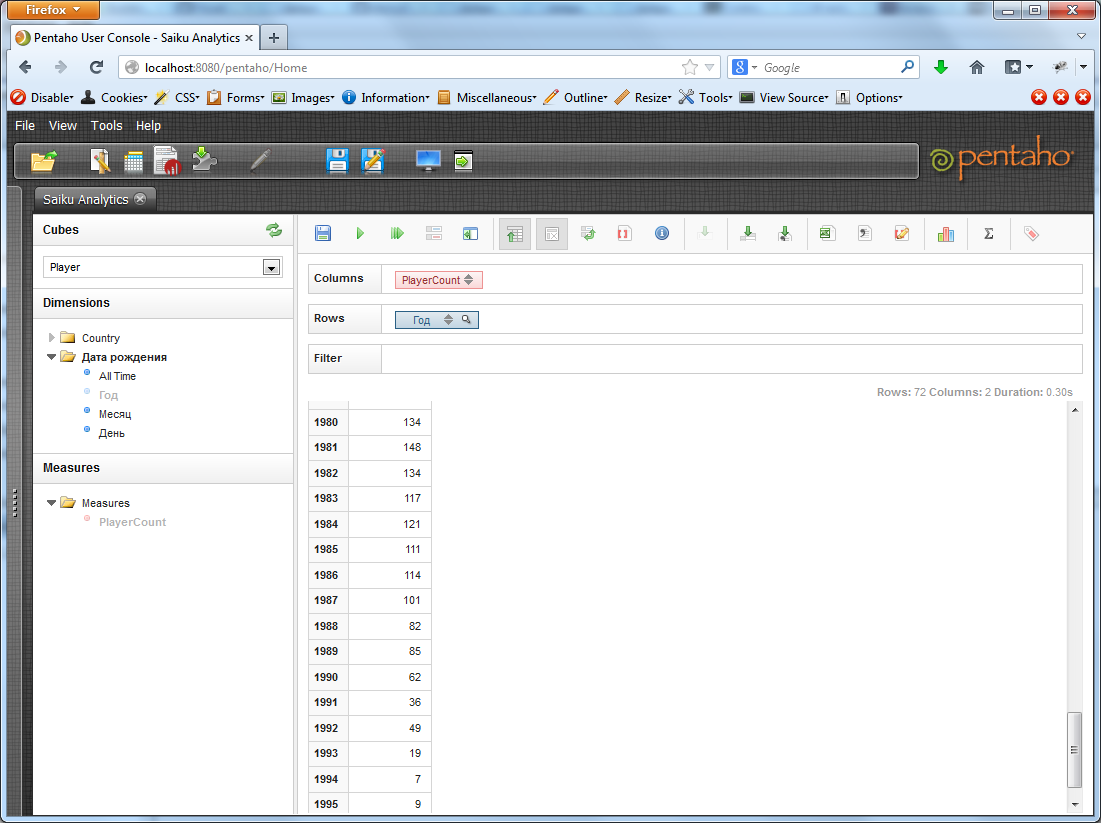
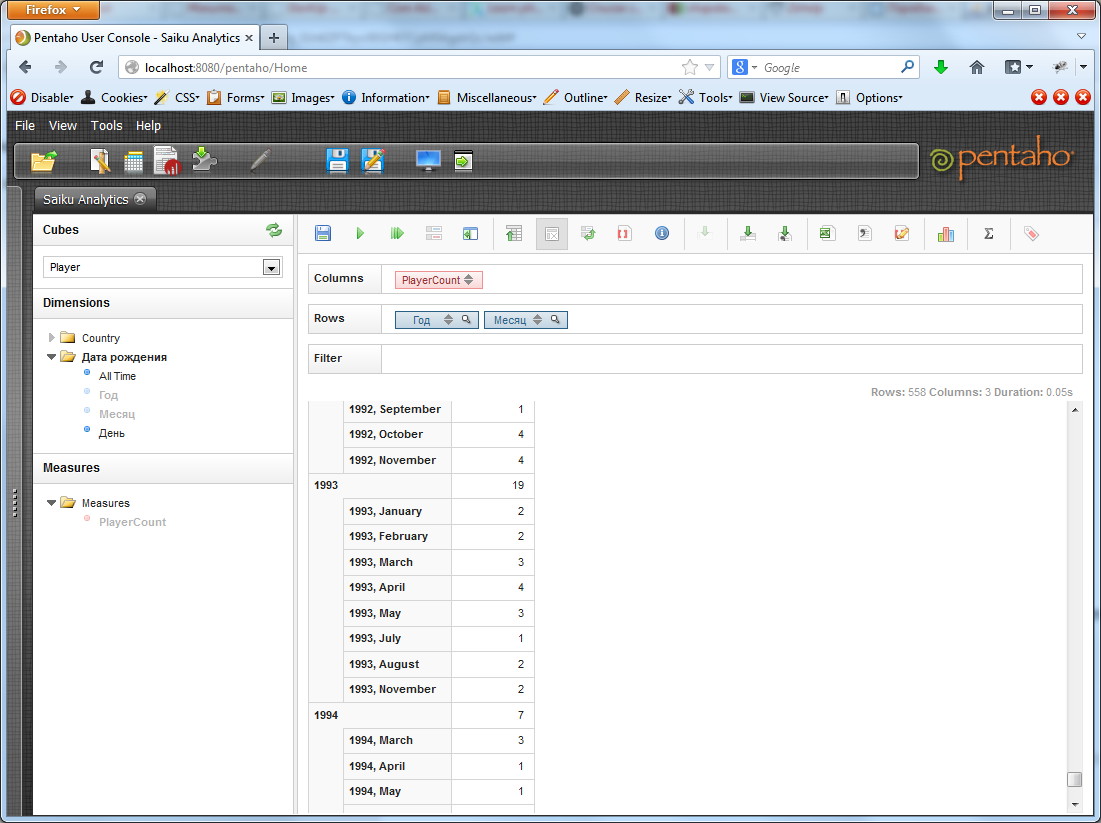
А теперь добавим к параметру «Год» еще и параметр «Месяц». Pentaho разобьет каждый из годов на месяцы и посчитает количество игроков, рожденных в определенный месяц каждого года. По умолчанию, отображаются только данные по месяцам, но если отжать в тулбаре кнопку «Hide Parents», то можно увидеть и суммарное количество игроков за данный год.
Но основная сила Pentaho, да и всего OLAP, собственно, не в таких простых выборках, а в срезах по нескольким измерениям одновременно. Т.е. например, найдем количество игроков каждой страны, рожденных после 1990 года.
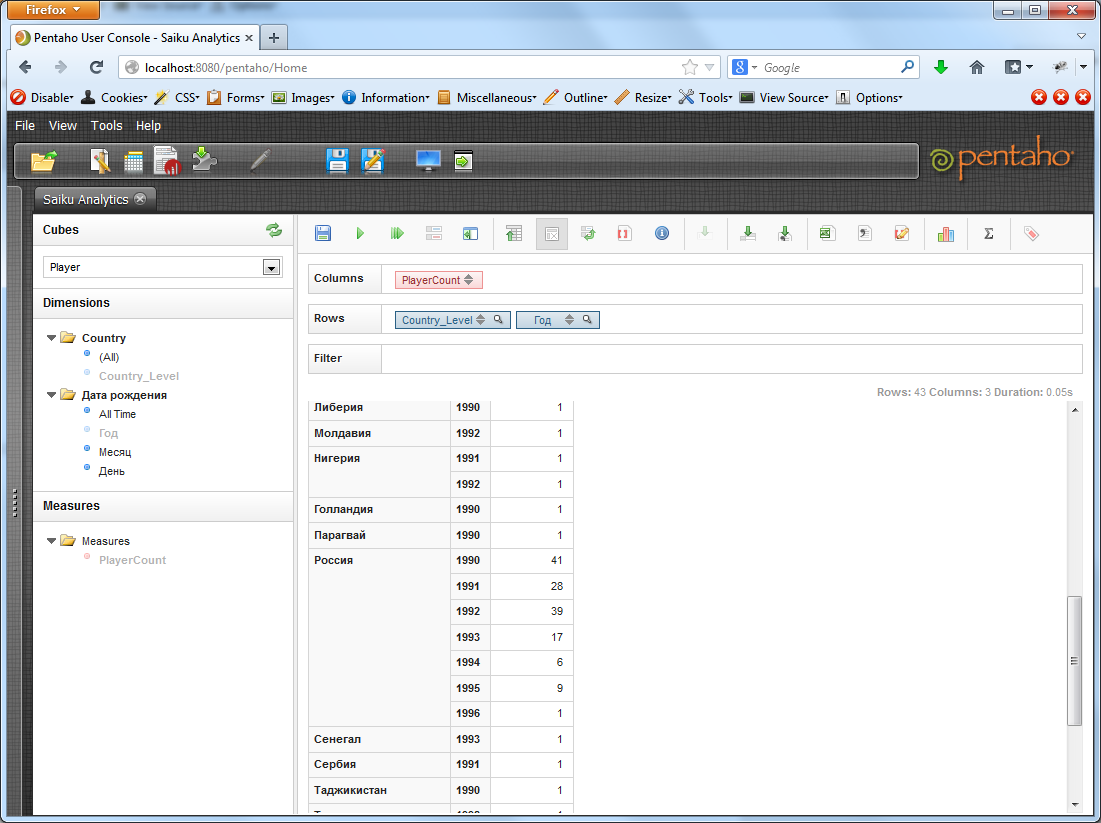
С увеличением количества метрик запросы могут становиться все более сложными и точечными, отражающими конкретную статическую потребность.
На этом наша длинная-длинная статья завершается. Надеюсь, данный туториал поможет кому-то по-новому взглянуть на решения OLAP или, быть даже может, ввести эти решения в своих организациях.
Здравствуйте, меня зовут Андрей и я по роду деятельности и не только, получаю много посылок с помощью Почты России. Соответственно очень мне нравится отслеживать их перемещение через сеть Интернет с помощью сервиса на сайте Почты России и сторонних сервисов. Те кто когда либо пробивал посылку на сайте Почты России знают насколько это неудобно, а может и не знают, может кому то нравится, мне нет, одну посылку еще можно отслеживать заучив трек номер наизусть, а если несколько то неудобно. У сторонних сервисов все намного лучше, но на бесплатном обслуживании проверка статуса посылки раз в сутки и нет приятных мелочей типа смс уведомления. Если оплатить тариф то становится совсем хорошо, почти все меня устраивало, пока не вспомнил что когда Почта ввела у себя на сервисе отслеживания каптчу, здесь на Хабре проскакивали сообщения о том что у Почты есть api для доступа к сервису трекинга. Статья на Хабре доступна и сейчас, называется «Клиент для SOAP API Почты России на Python». Так вот, я тогда подумал а может попробовать получить доступ и написать свой скрипт, только то что мне нужно и ничего лишнего. На самом сайте Почты России я не нашел никакой информации как к ним подключится, может плохо искал. В статье, о которой писал выше, предлагалось в свободной форме написать на fc@russianpost.ru, что я и сделал. Так просто и написал, что мне нужен доступ к отслеживанию статусов РПО по SOAP протоколу, зачем мне это нужно особо в подробности не вдавался. Каково же было моё удивление когда мне ответили да ещё и так быстро, минут через 15 примерно. Ответ был следующего содержания:
Доступ предоставляется юридическим лицам и ИП. Во вложении заявка на подключение к сервису. Скан-копию оформленной и заверенной заявки направляйте на этот адрес.
Тут следует сказать что я ИП и у меня есть печать. Во вложении действительно был файл в формате doc. Сама заявка очень простенькая нужно указать наименование предприятия, инн, почтовый индекс, ф.и.о., контактный телефон, e-mail. Все это я заполнил, распечатал, подписал, поставил печать, отсканировал и отправил обратно. Все это происходило в пятницу, после отправки, до конца рабочего дня ответа не пришло, и я спокойно отправился на выходные с мыслю что подожду с понедельника дня три и если ответа не будет напишу на этот адрес еще раз. В понедельник пришел ответ следующего содержания:
Во вложении учетные данные для подключения, адрес доступа и механизмы интеграции.
Во вложении было два файла, текстовый, с логином, паролем и url сервиса для отправки запросов. Второй назывался Интеграционные механизмы взаимодействия с сервисом отслеживания РПО, и представлял из себя документ в формате doc на 16 страниц.
Теперь немного о самой реализации доступа. Как уже понятно доступ осуществляется по протоколу SOAP в режиме WSDL, в присланных документах есть вся необходимая информация для формирования запросов. Можно особо не заморачиваться и взять готовый скрипт на python из статьи выше и на его основе что-нибудь сделать, лично я с python не очень дружу. Свой сервис я пишу на php. С soap знаком тоже поверхностно, поэтому сейчас активно его осваиваю. Очень хорошая статья по soap здесь на Хабре, во всяком случае мне помогла понять что к чему. И ещё на github в результатах поиска по ключевому слову russianpost есть готовые классы на php для формирования запросов к soap api Почты России. Вот такая история.
Hi,
I’m trying to evaluate pentaho bi server 4.0 enterprise edition.
I tried to create some new users and assign them roles.
I looked at the forum posts that if we want to do this, we should log into application as admin.
I tried to input ‘password’ as admin password (as I see in another thread that this is the default password for admin) but I can’t get logged in.
How can I log into pentaho bi server as admin and create new user ?
Any help would be greatly appreciated
Regards,
You have to login in into the administration console not the BI-server (by default localhost:8099).
Default login is admin/password.I hope this helps.
thanks for the reply hans…
I tried to start pentaho enterprise console (pentaho administration console for bi-server enterprise edition ?) by double clicking start-pec.bat.
it turns out that the password for the admin is “pentaho”, not “password”.
regardsAh my bad !
but i’m glad you found it !Strangely, I tried to input admin/pentaho as username/password pair in local machine.. it works. but when I tried to input the same credentials in another remote machine in my network (using the same installation file), I can not get logged in.
I’ve also found out that password information is stored in (your-pentaho-enterprise-console-folder)/resource/config/login.properties file in an encrypted form.
My question is can we change this value (changing this password) in this file so we can log into pentaho enterprise console ?
ThanksYes you can !
to get the encrypted form of the password (please keep a copy of the original in case it fails) you have to use following command (assuming you use linux)
java -cp lib/jetty-6.1.2.jar:lib/jetty-util-6.1.9.jar org.mortbay.jetty.security.Password MyUsername MyPassword
You have to check the jetty version under enterprise console/lib and have it running.
after a restart of the server you should be able to login using the new username/passwordhope this helps
Ok Hans, thanks a lot for the reply. I’ll try that..
Originally Posted by hansva
hope this helps
- Forum
- Pentaho Users
- BI Platform
Dear sirs,
joe, pat, suzy etc doensn’t work. Every time i got the same message: ‘Login Error’.
Could you help me?
Thanks in advance.
Enterprise Console/Administration Console:
User: admin
Password: passwordif you haven’t changed anything you must be able to log in with this credentials
I’m having exactly the same problem as romualdo. I can get into the admin console, but not the user console – I get Login Error. I have tried creating a new user but that doesn’t work either. I can only assume the user console app is not managing to connect to the database where the authentication info is stored.
I’d be really grateful for any ideas on how I could go about debugging where the problem lies.
Last edited by julier; 04-17-2009 at .
Please can you help me debug this installation?
Have other people had problems with the latest windows package installer? There seem to be at least 2 of us.
hi! not sure if this is what u need..
you can go to these places to check the settings for the datasources..
these are the settings necessary for setting up datasources for pentaho
i am using biserver-ce v2.0.0 stable
Hi, thanks for replying. I had a look around the files you mention, and I didn’t see anything particularly alarming. I did see the password ‘password’ in a number of places though, so in desparation I tried uninstalling and reinstalling using that password for everything. But I still get the same problem.
Has the v3 installer been tested on XP? I can’t imagine what could be different about my setup. I did not have any related software installed on this machine, i.e. no MySQL, Apache etc.
This is shaping to be the shortest product evaluation I’ve ever done.
Hi, I had exactly the same problem when i tried the EE in a VMWare running Windows XP Prof. Directly on my Notebook with Vista it worked fine.
hi!
in case your problem has not been solved..Firstly, if MySQL is for storing of data for datawarehouse for pentaho, did you see a similar configuration for MySQL when you browse through those 3 files?
If no, maybe you should set them according to your new password and database name.
If yes, make sure you have the settings set to your new password
OracleSample/type=javax.sql.DataSource OracleSample/driver=oracle.jdbc.driver.OracleDriver OracleSample/url=jdbc:oracle:thin:@localhost:1521:XE OracleSample/user=your_user_for_this_database OracleSample/password=your_own_password where OracleSample is your database name that you have created. Make sure these settings are same for these 3 files. The url and driver string is different for MySQL, you can google for that, i forgot what is it.
If you are using MySQL for password login, you have to change some other settings in other files? Let me know again if it is the case.
Hi, thanks for the suggestions. Firstly, thanks cwendl, I tried using localhost, but this did not help.
To answer your question Choon Boon, I installed Pentaho on a clean XP machine that did not have a database installation. I got the impression that the Pentaho bundle contained mysql and all it needed to run. Is that wrong? After installation I found I could connect via the mysql client installed by pentaho, so all seemed ok.
SampleData/type=javax.sql.DataSource SampleData/driver=org.hsqldb.jdbcDriver SampleData/url=jdbc:hsqldb:hsql://localhost/sampledata SampleData/user=pentaho_user SampleData/password=password
The context.xml seems more about the admin user & password, and that’s working fine. I’m not sure what to look for in the web.xml.
Hi!
If MySQL is bundled, then i supposed it should have a settings similar to that “SampleData”. Its either that or its already integrated in hsqldb.i am not too sure as i am not too familar with MySQL and that hsqldb.
All Database that pentaho needs to connects to, needs to have settings in these 3 files in order to work.
Both are using hsqldb.
Hi, has anybody found the issue with this problem? I’m currently experiencing the same on one of my servers…
My env is on a Linux Server with
MySQL 5.0.18
Java 1.6.0_18
Biserver-ce-3.5.0 stable version
c3p0-0.9.12
mysql connector 5.0.7Last edited by honos; 02-22-2010 at .
Hi,
To All:
While I have not figured out where or how if you have a mysql database try using the password of ‘cGFzc3dvcmQ=’
To any of the Senior members
I know it has to deal with applicationContext-spring-security-jdbc.xml
yet I am unsure which bean to set it as..
Does not work can someone tell me what it should be to match the hash string in the mysql db?
If you have switched to applicationContext-spring-security-jdbc.xml as opposed to the default (which is applicationContext-spring-security-hibernate.xml) the default passwordEncoder is PlaintextPasswordEncoder. If you have changed it to Md5PasswordEncoder then you must pre-hash the passwords before storing them in the database. The password encoder applies only to password storage, not to password transit. You should enter your passwords in plaintext in the UI and Spring Security will apply the password encoder before comparing the password to the database.
Originally Posted by honos
Hi!
Could you please tell me what are the exact tables in which you found the data to be corrupted? I am facing the same issue and am unable to resolve it even with a fresh installation.
Tags for this Thread
Posting Permissions
- You may not post new threads
- You may not post replies
- You may not post attachments
- You may not edit your posts
- BB code is On
- Smilies are On
- [IMG] code is On
- [VIDEO] code is On
- HTML code is Off
Forum Rules
Privacy Policy | Legal Notices | Safe Harbor Privacy Policy
Copyright © 2005 – 2019 Hitachi Vantara Corporation. All Rights Reserved.
- Forum
- Pentaho Users
- BI Platform
Pentaho User Console doesn’t work anymore
Hi,
Did anyone have the same problem? Or is Pentaho just telling me “It’s friday afternoon, go home?”
Hi,
check logs/catalina.out
and see if there’s a stack or anything
Hi,
the logs don’t show anything unnormal but I think I found the problem.
On friday I installed the latest CDF by hand and I had to set the parameter “solution-path” in the web.xml. It worked fine, only after a couple of restarts, I couldn’t start mantle anymore. So I deleted the parameter in thew web.xml and Mantle works again.Sounds strange to me, but from now on I just won’t touch the CDF again.
You didn’t have to change solution path in web.xml for CDF it would already be set to the right place. You just needed to add the dashboard pointers.
if its empty it just rolls back to the default pentaho-solutions. Either way, you can see xactions and things then your solution path is set correctly. In BI 2.0 most of the configuration stuff has been moved to pentaho-solutions so if it cant find it you can pretty much guarentee it bombing.
Hi,
It worked fine but after I tried an invalid MDX query, mantle wouldn’t work anymore. I have no idea why.
I’ve started to hit this same issue yesterday on 3.5. The console just never loads. Just the loading icon and the message “Pentaho User Console is Loading…”. I may just start from scratch to see if that does it.
I had the more or less same problem testing some previous builds get from the Hudson CI system.
In my case the “Pentaho User Console is Loading… Please Wait” remains for some time. In that case loging of and the relogging everything wored fine. SO I assumed it was a temporary problem…I just recompiled a fresh set of 3.5 sources get from pentaho repository the day before yesterday, packeged it, deployed and tried and it works fine.
Apologize me for some mistyping. I was writing at warp speed :-). I rewrite the thread below for clarity.
I just recompiled a fresh set of 3.5 sources get from pentaho repository the day before yesterday. I packaged it, deployed and tried and it worked fine.
I faced with similar situation and finally solved.
My situation is below, hope it will help you.
The installation for Pentaho was done successfully in April
and I was able to logged in at that time.
But I can not load user console as you described today.
Reboot for all the services and OS does not take effect.
I finally resolve it by erasing all temporary internet files and histories.
Environment
Pentaho User Console 4.1.0 GA
Internet Explorer 7
Posting Permissions
- You may not post new threads
- You may not post replies
- You may not post attachments
- You may not edit your posts
- BB code is On
- Smilies are On
- [IMG] code is On
- [VIDEO] code is On
- HTML code is Off
Forum Rules
Privacy Policy | Legal Notices | Safe Harbor Privacy Policy
Copyright © 2005 – 2019 Hitachi Vantara Corporation. All Rights Reserved.


